【立委按】端口(portals),兵家必争。bots,热门中的热门。白老师说,背后的ai才是战略布局的重中之重。又说,平台和服务,非巨头不能。问题是哪家巨头明白战略布局的精要所在。对于中文深度理解,水很深很深。大浪淘沙,且看明日之ai,竟是谁家之天下。不是特别有insights和分量的,我是不会翻译的(尽管有了神经翻译助力,也搭不起那个时间)。白老师绝妙好文,值得咀嚼。(By the way, 最后一段的想象力,秒杀所有科幻作家。)
“入口载体”之争
最近,亚马逊旗下的智能音箱产品 Echo 和出没于 Echo 中的语音助手 Alexa 掀起了一股旋风。不仅智能家居业在关注、人工智能创业公司在关注,IT巨头们也在关注。那么,Alexa 到底有什么独到之处呢?
Recently, Amazon's AI product Echo and its voice assistant Alexa set off a whirlwind in the industry. It has drawn attention from not only the smart home industry but also the AI start-ups as well as the IT giants. So, what exactly is unique about Alexa?
有人说,Alexa 在“远场”语音识别方面有绝活,解决了“鸡尾酒会”难题:设想在一个人声嘈杂的鸡尾酒会上,一个人对你说话,声音虽不很大,但你可以很精准地捕捉对方的话语,而忽略周边其他人的话语。这手绝活,据说其他语音厂商没有,中国连语音处理最拿手的科大讯飞也没有。
Some people say that Alexa has solved the challenging "cocktail party" problem in speech recognition: imagine a noisy cocktail party, where a person is chatting with you, the voice is not loud, but you can accurately capture the speech with no problem while ignoring the surrounding big noise. Alexa models this amazing human capability well, which is said to be missing from other leading speech players, including the global speech leader USTC iFLYTEK Co.
有人说,Alexa 背后的“技能”极其丰富,你既可以点播很多节目,也可以购买很多商品和服务;既可以操控家里的各款家电设备,也可以打听各类消息。总而言之,这是一个背靠着强大服务资源(有些在端,更多在云)的语音助手,绝非可与苹果的 Siri 或者微软的小冰同日而语。
Others say that behind Alexa are very rich cross-domain know-hows: one can ask Alexa for on-demand programs, he can also buy goods and services through it; it can be instructed to control the various appliances of our home, or inquire about all kinds of news. All in all, this is a voice assistant backed by a strong service (with some resources local, and more in the cloud). Apple's Siri or Microsoft's Little Ice are believed to be by no means a match for Alexa in terms of these comprehensive capabilities.
端方面的出色性能,加上端+云方面的庞大资源,构成了 Alexa 预期中的超强粘性,形成了传说中巨大的入口价值。这也似乎是Alexa在美国市场取得不俗业绩的一个说得通的解释。有相当一部分人意识到,这可能是一个巨大的商机,是一个现在不动手说不定将来会追悔莫及的局。尽管在美国以外的其他市场上,Alexa的业绩并不像在美国市场那样抢眼,但是这股Alexa旋风,还是刮遍了全球,引起了同业人士的高度紧张和一轮智能音箱模仿秀。
The excellent performance by the end device, coupled with the huge cloud resources in support of the end, constitute Alexa's expected success in customers' stickiness, leading to its legendary value as an information portal for a family. That seems to be a good reason for Alexa's impressive market performance in the US. A considerable number of people seem to realize that this may represent a huge business opportunity, one that simply cannot be missed without regret. Although in other markets beyond the United States, Alexa's performance is not as eye-catching as in the US market, this Alexa whirlwind has till been scraping the world, leading to the industry's greatest buzz and triggering a long list of smart speaker simulation shows.
Alexa 动了谁的奶酪?抢了谁的饭碗?怎样评价 Alexa 的入口价值?怎样看待入口之争的昨天、今天、明天?
Hence the questions: What are the effects of this invention of Alexa? Who will be affected or even replaced? How to evaluate Alexa's portal value? Where is it going as we look into the yesterday, today and tomorrow of this trend?
我们不妨来回顾一下“入口”的今昔变迁。所谓“入口”,就是网络大数据汇聚的必经之地。从模式上看,我们曾经经历过“门户网站”模式、“搜索引擎”模式和“社交网络”模式,目前新一代的入口正在朝着“人工智能”模式迁移。从载体上看,“门户网站”和“搜索引擎”模式的载体基本上是PC,“社交网络”模式的载体基本上是以智能手机为主的端设备。“人工智能”模式有可能的改变载体吗?换句话说,Echo-Alexa 软硬合体,能够以人工智能的旗号,从智能手机的头上抢来“入口载体”的桂冠吗?
We may wish to reflect a bit on the development of portals in the IT industry history. The so-called "portal" is an entry point or interface for an information network of large data flow, connecting consumers and services. From the model perspective, we have experienced the "web portal" model, the "search engine" model and more recently, the "social network" model, with the on-going trend pointing to a portal moving in the "artificial intelligence" mode. From the carrier perspective, the carrier for the"web portal" and "search engine" models is basically a PC while the "social network" model carrier is mainly a smart phone-based end equipment. Does the "artificial intelligence" model have the potential to change the carrier? In other words, is it possible for the Echo-Alexa hardware-software combination, under the banner of artificial intelligence, to win the portal from the smart phone as the select point of human-machine interface?
本人认为,这是不可能的。原因有三。
I don't think it is possible. There are three reasons.
第一,场景不对。哪怕你抗噪本事再强大,特定人跟踪的本事再大,只要安放地点固定,就是对今天已经如此发达的移动场景的一种巨大的倒退。试想,家庭场景的最大特点就是人多,人一多,就形成了个小社会,就有结构。谁有权发出语音指令?谁有权否定和撤销别人已经发出的语音指令?最有权的人不在家或者长期沉默,听谁的?一个家庭成员如果就是要发出一个不想让其他家庭成员知道的私密语音指令怎么办?个人感觉,语音指令说到底还是个体行为大于家庭行为,私密需求大于开放需求。因此,家庭语音入口很可能是个伪命题。能解析的语音指令越多,以家庭场景作为必要条件的语音指令所占比重就越少。
First, the scene is wrong. Even if Alexa is powerful with unique anti-noise ability and the skills of tracking specific people's speech, since its location is fixed, it is a huge regression from today's well-developed mobile scenes. Just think about it, the biggest feature of a family scene is two or more individuals involved in it. A family is a small society with an innate structure. Who has the right to issue voice commands? Who has the authority to deny or revoke the voice commands that others have already issued? What happens if the authoritative person is not at home or keeps silent? What if a family member intends to send a private voice instruction? To my mind, voice instruction as a human-machine interaction vehicle by nature involves behaviors of an individual, rather than of a family, with privacy as a basic need in this setting. Therefore, the family voice portal scene, where Alexa is now set, is likely to be a contradiction. The more voice commands that are parsed and understood, the less will be the proportion of the voice commands that take the home scenes as a necessary condition.
第二,“连横”面临“合纵”的阻力。退一步说,就算承认“智能家居中控”是个必争的入口,智能音箱也面临其他端设备的挑战。我们把聚集不同厂家家居设备数据流向的倾向称为“连横”,把聚集同一厂家家居设备数据流向的倾向称为“合纵”。可以看出,“连横”的努力是对“合纵”的生死挑战,比如海尔这样在家庭里可能有多台智能家居设备的厂商,如非迫不得已,自家的数据为什么要通过他人的设备流走呢?
Second, the "horizontal" mode of portal faces the "vertical" resistance. Even if we agree that the "smart home central control" is a portal of access to end users that cannot be missed by any players, smart speakers like Alexa are also facing challenges from other types of end equipment. There are two types of data flow in the smart home environment. The horizontal mode involves the data flow from different manufacturers of home equipment. The vertical mode portal gathers data from the same manufacturer's home equipment. It can be seen that the "horizontal" effort is bound to face the "vertical" resistance in a life and death struggle. For example, the smart refrigerator and other smart home equipment manufactured by Haier have no reasons to let go its valuable data and flow it away to the smart speaker manufacturers.
第三,同是“连横”的其他端设备的竞争。可以列举的有:家用机器人、家庭网关/智能路由器、电视机、智能挂件等。这些设备中,家用机器人的优势是地点无需固定,家庭网关的优势是永远开机,电视机的优势是大屏、智能挂件(如画框、雕塑、钟表、体重计等)的优势是不占地方。个人感觉,智能音箱面对这些“连横”的竞争者并没有什么胜算。
Third, the same struggle also comes from other competitions for the "horizontal" line of equipment, including house robots, home gateway / intelligent routers, smart TVs, intelligent pendants and so on. The advantage of the house robots is that their locations need not be fixed in one place, the advantage of the home gateway is that it always stays on, the TVs' advantage lies in their big screens, and intelligent pendants (such as picture frames, sculptures, watches, scales, etc.) have their respective advantage in being small. In my opinion, smart speakers face all these "horizontal" competitions and there does not seem to be much of a chance in winning this competition.
综上所述,Echo-Alexa 的成功,具有很强的叠加特点。它本质上是亚马逊商业体系的成功,而不是智能家居设备或者语音助手技术的成功。忽略商业体系的作用,高估家庭入口的价值,单纯东施效颦地仿制或者跟随智能音箱,是没有出路的。个人觉得,智能手机作为移动互联时代的入口载体,其地位仍然是不可撼动的。
In summary, the Echo-Alexa's success comes with a strong superposition characteristic. It is essentially a success of the Amazon business system, rather than the success of smart home appliances or the voice assistant technology. Ignoring the role of its supporting business system, we are likely to overestimate the value of the family information portal, and by simply mimicking or following the smart speaker technology, there is no way out. Personally, I feel that the smart phone as the carrier of an entry point of information in the mobile Internet era still cannot be replaced.
语音交互时代真的到来了吗?
Is the era of voice interaction really coming?
IT巨头们关注 Alexa 还有一个重要的理由,就是由 Alexa 所代表的语音交互,或许开启了人机交互的一种新型范式的兴起。当年,无论是点击模式的兴起还是触摸模式的兴起,都引发了人机交互范式的革命性变化,直接决定了IT巨头的兴亡。点击模式决定了 wintel 的崛起,触摸模式决定了 wintel 被苹果的颠覆,这些我们都以亲身经历见证过了。如果语音交互真的代表了下一代人机交互范式,那么 Alexa 就有了人机交互范式的代际转换方面的象征意义,不由得巨头们不重视。
One important reason for the IT giants to look up to Alexa is that the voice interaction represented by Alexa perhaps opens a new paradigm of human-computer interaction. Looking back in history, the rise of the click-mode and the rise of the touch-mode have both triggered a revolutionary paradigm shift for human-computer interaction, directly determining the rise and fall of the IT giants. The click-mode led to the rise of Wintel, the touch mode enabled Apple to subvert Wintel: we have witnessed all these changes with our own eyes. So if the voice interaction really represents the next generation paradigm for human-computer interaction, then Alexa has a special meaning as the precursor of the human-computer interaction paradigm shift. The giants simply cannot overlook such a shift and its potential revolutionary impact.

然而个人认为,单纯的语音交互还构不成“代际转换”的分量。理由有三:
However, personally, I do not think that the speech interaction alone carries the weight for an "intergenerational revolution" for human-machine interaction. There are three reasons to support this.
第一,语音本身并不构成完整的人机交互场景。人的信息摄入,百分之八十以上是视觉信息,在说话的时候,经常要以视觉信息为基本语境,通过使用指示代词来完成。比如指着屏幕上一堆书当中的一本说“我要买这本”。就是说,语音所需要的语境,有相当部分来自视觉的呈现,来自针对和配套可视化对象的手势、触摸或眼动操作。这至少说明,我们需要multi-modal人机交互,而不是用语音来取代其他人机交互手段。
First, the speech itself does not constitute a complete human-computer interaction scene. People's information intake, more than 80% of times, involves the visual information. When speaking, we often take some visual information as basic context, through the use of a pronoun to refer to it. For example, pointing to a book on the screen, one may say, "I want to buy this." In other words, a considerable part of the context in which the speech is delivered comes from the visual presentation, ranging from gestures, touches or eye movements that target some visual objects. This at least shows that we need multi-modal human-computer interaction, rather than using voice alone to replace other human-computer interaction vehicles.
第二,目前语音输入还过不了方言关。中国是一个方言大国,不仅方言众多,而且方言区的人学说普通话也都带有方言区的痕迹。“胡建人”被黑只是这种现象的一个夸张的缩影。要想惠及占全国总人口一半以上的方言区,语音技术还需要经历进一步的发展和成熟阶段。
Second, the current speech recognition still cannot handle the dialect well. China is a big country with a variety of dialects. Not only dialects, but also the people in dialect areas speack Mandarin with a strong accent. To benefit more than half of the total population in the dialect areas, the speech technology still needs to go through a stage of further development and maturity.
第三,目前语音输入还很难解决“转义”问题。所谓转义问题就是当语音指令的对象是语音输入本身的时候,系统如何做出区分的问题。人在发现前一句说的有问题需要纠正的时候,有可能需要用后一句话纠正前一句话,这后一句话不是正式的语音输入的一部分;但也有可能后一句话并不是转义,而是与前一句话并列的一句话,这时它就是语音输入的一部分。这种“转义”语音内容的识别,需要比较高级的语义分析技术,目前还不那么成熟。
Third, the current speech recognition still has difficulty in solving the "escape" problem. The so-called escape problem involves the identification of scenarios when the speech refers to itself. When people find there is an error in the first utterance and there is a need to correct it, they may choose to use the next sentence to correct the previous sentence, then this new sentence is not part of the naturally continuous speech commands, hence the need for "being escaped". But it is also possible that the latter sentence should not be escaped, and it is a sentence conjoined with the previous sentence, then it is part of the normal speech stream. This "escape" identification to distinguish different levels of speech referents calls for more advanced semantic analysis technology, which is not yet mature.
所以,以语音输入目前的水平,谈论语音输入的“代际转换”或许还为时尚早。甚至,语音可能只是一个叠加因素,而并不是颠覆因素。说未来会进入multi-modal输入的时代,说不定更加靠谱一点。
So, considering the current level of speech technology, it seems too early to talk about the "intergenerational revolution". Furthermore, speech may well be just one factor, and not necessarily a disruptive one. It seems more reasonable to state that the future of human-computer interaction may enter an era of multi-modal input, rather than speech alone.
语义落地是粘性之本
The semantic grounding is the key to the stickiness of users.
语义这个字眼,似乎被某些人玩得很滥,好像会分词了就摸到语义了,其实不然。语义的水很深。
Semantics as a term seems abused in all kinds of interpretations. Some even think that once words are identified, semantics is there, which is far from true. The semantics of natural languages is very deep and involves a lot. I mean a lot!
从学术上说,语义分成两个部分,一个叫“符号根基”,讲的是语言符号(能指)与现实世界(也包括概念世界)中的对象(所指)的指称关系;另一个叫“角色指派”,讲的是语言符号所指的现实或概念对象之间的结构性关系。符号根基的英文是“symbol grounding”,其中的 grounding 就有落地的意思。所以,我们说的语义落地,无论学术上还是直观上,都是一致的。Siri 在通信录、位置、天气等领域首开了在移动互联设备上实现语义落地的先河,这几年语义落地的范围越来越广。
From the academic point of view, semantics is divided into two parts. One called "symbol grounding", which is about the relationship of the language symbol (signifier) and its referent to the real world entity (including the conceptual world). The second is called "role assignment", which is about the relationship between the referents of the language symbols in the reality. Siri is the pioneer in the mobile semantic grounding realized in the domain apps such as Address, Map and Weather. The past few years have seen the scope of semantic grounding grow wider and wider.

前面说了,“端方面的出色性能,加上端+云方面的庞大资源,构成了 Alexa 预期中的超强粘性”。我们在这一节里面要进一步探讨:“端的性能”和“端+云的资源”这两者中,谁是产生 Alexa 粘性的更根本原因?笔者无意玩什么“都重要,谁也离不开谁”之类的辩证平衡术,那是便宜好人,说起来冠冕堂皇,做起来毫无方向。坦率地说,如果归因错误,那么就会产生投入方向的错误。而投入方向的错误,将使模仿者东施效颦,输得体无完肤。
Let me review what I said before: "the excellent performance by the end equipment, coupled with the huge cloud resources in support of the end, constitute the Alexa's expected success in users' stickiness". We can further explore along this line in this section. Between "the performance by the end equipment" and "the cloud resources in support of the end", which is the root cause for Alexa's stickiness with the customers? I do not intend to play the trick of dialectical balance by saying something like both are important and no one can do the job without the other. That is always true but cheap, and it gives no actionable insights. The consequence includes possible blind investments in both for the copycat, such investments may well lead to a complete failure in the market.
作者认为,“端的性能”是硬件对场景的适应性。这充其量是“好的现场体验”。但没有实质内容的“好的现场体验”会很快沦为玩具,而且是不那么高档的玩具。没有“有实质意义的服务”就不可能产生持久的粘性,而没有持久的粘性就充当不了持久的数据汇集入口。然而,“有实质意义的服务”,一定源自语义落地,即语音指令与实际服务资源的对接,也就是 Alexa 的所谓“技能”。底下所说的语义落地,都是指的语音指令与无限可能的实际服务资源对接这种落地。
The author argues that "the performance by the end equipment" is about the adaptability of the hardware to the scene. This is at best about a "good live experience" of users. But a product with "good user experience" without real content will soon degrade to a toy, and they cannot even count as high-end toys. If there is no real "meaningful service" associated, there will be no sustainable stickiness of customers. Without user stickiness, they cannot become sustainable data collection entry points as a data flow portal. However, any associated "meaningful services" must come from the semantic grounding, that is, the connection from a speech command with its corresponding actual service. This is the essence behind Alexa's so-called "know-hows." Semantic grounding as mentioned hereafter all refers to such connection from the speech command with infinitely possible actual service resources.
语义落地需要一个强大的、开放领域的NLP引擎。服务资源千千万万,不可能局限在一个或少数领域。一个只能面对封闭领域的NLP引擎,无法胜任这样的任务。能够对接开放领域,说明这个引擎一定在语义分析上有非同寻常的功力,一定在语义知识的表示和处理方面走在了正确的道路上。在这方面,英语做得好,不一定汉语做得好。还不了解汉语在开放领域的NLP引擎是一个什么样难度的人,不可能做出规模化的语义落地效果。这方面的技术壁垒可以在做同一个事情的公司间拉开有如天壤之别的巨大差距。
Comprehensive semantic grounding requires a strong open-domain NLP engine. Service resources are so diverse in tens of thousands, and they can hardly be confined to one or only a few narrow domains. An NLP engine functioning only in a narrow domain cannot do this job well. To work in the open domain requires an engine to be equipped with extraordinary capacity in the semantic analysis, and it must be on the right path in the semantic knowledge representation and processing. In this regard, even if an English engine is doing decently well, it does not necessarily mean the Chinese counterpart will work well. For those who do not yet understand the difficulty and pain points of the Chinese NLP engine in the open domain, it is hardly possible to expect them to achieve large-scale semantic grounding effects. Such technology barriers can set apart a huge gap in products attempting to do the same thing in the market between companies equipped with or without deep semantic capabilities.
语义落地需要对服务资源端的接口做出工程化的适配。这同样是一个非常艰巨的任务,而且是拼资源、拼效率、拼管理的任务。小微规模的初创公司不可能有这样的资源整合能力和工程组织能力,这一定是大公司的强项。有人说,我由小到大行不行?我说,不行,时间不等人。在语义落地领域,如果不能在短时间内爆发,等着你的就是灭亡。
Semantic grounding requires an engineering adaptation at the interface to the service resources. This is also a very difficult task, and it involves competitions in the scale of resources as well as efficiency and management. Start-up companies can hardly have such a resource integration capacity and the engineering organization capabilities, these are the strength of large companies. Some people say that I can start small and gradually scale up, okay? I said, no, time does not wait for people. In the area of semantic grounding, if products are not developed in a relatively short time to capture the market, there are little chances for survival.
语义落地还需要对人机对话场景本身的掌控能力。这涉及语境感知、话题切换、情感分析、语言风格选择、个性塑造等多项技术,不一而足。语音助理不见得都是越“贫”越“萌”越好,比如适度的渊博、犀利甚至粗鲁,也都可以是卖点。
Semantic grounding also calls for the ability to manage the man-machine interactive scene itself. This involves a variety of technologies such as contextual perception, topic switching, sentiment analysis, language style selection, personality shaping and many others. A speech assistant is not necessarily the best if it only mimics human's eloquence or seemingly likable ways of expressions. Skills such as moderate profoundness or sharpness in arguments and even some rudeness at times can all be selling points as an intelligent assistant.
所以,我们强调语义落地对 Alexa 用户粘性的决定性作用,强调庞大服务资源对于 Alexa 成功故事的决定性贡献。在中国,没有与亚马逊规模相当、服务资源体量相当的超大型互联网企业出手,没有对面向汉语的开放领域NLP引擎开发重量级团队的出手,单凭语音技术是不可能产生这样的用户粘性的。
Therefore, we would point out the key role of semantic grounding on the stickiness of Alexa users, emphasizing the decisive contribution of large service resources behind Alexa's success story. In China, if Chinese IT giants with a comparable size of the Amazon service resources do not take the lead, coupled by a solid open domain Chinese NLP engine with a star team, the speech technology alone has no way to generate such a user stickiness as we see in Alexa.
谁会胜出?
这年头,一切不以获取用户数据为目的的端设备都是耍流氓。智能手机独领风骚多年了,各类智能家居连横合纵也斗了有几年了。Alexa 的横空出世,给了业界很多刺激和启示,但地盘属谁,并没有盖棺论定。大家还有机会。但是就端云结合、入口和入口载体结合形成数据闭环这件事,方向性、趋势性的东西不可不查,否则机会就不是你的。
Who will win then?
In essence, it is all about gathering the user data by the end equipments. Smartphones dominate the industry for years, all kinds of smart home solutions across the verticals have also been fighting for several years now. Alexa's coming to the market stirs the industry with a lot of excitement and revelations, but it is far from what is all set. We still have opportunities. But keep in mind, it cannot be overemphasized to look into issues involving the combination of the end devices with the cloud and the combination between the entry point and the entry point carrier to form a closed-loop data stream. If we lose the sense of directions and trends in these issues, the opportunity will not be ours.
什么是方向性、趋势性的东西呢?听我道来。
第一,人工智能一定是下一代的入口模式。也就是说,各种对服务的需求,必将最终通过人工智能的多通道输入分析能力和人机互动优势,从端汇集到云;各种服务资源,必将最终借助人工智能的知识处理与认知决策能力,从云对接到端。你不布局人工智能,未来入口肯定不是你的。
So what is the direction and what are the trends? Let me give an analysis.
First, artificial intelligence is bound to be the next generation portal. In other words, all kinds of service needs will inevitably go from the end devices to the cloud through the artificial intelligence multi-channel input analysis, leveraging the human-computer interaction advantages. The variety of service resources will eventually use the knowledge of artificial intelligence and cognitive decision-making ability, to provide to users from the cloud to the end. If you do not lay out a roadmap in developing artificial intelligence, the future portal is definitely not yours.
第二,智能手机在相当长一段时间内,仍然是入口载体事实上的“盟主”,地位不可撼动。人走到哪里,通信节点和数字身份就跟到哪里,对现场的感知能力和作为服务代言者的app就跟到哪里。在入口载体所需要的个人性、私密性和泛在性这几个最关键的维度上,还没有哪一个其他端设备能够与智能手机相匹敌。
Second, the smartphone for a long time to come will stay as defacto chief carrier. Wherever is the person going, the communication node and the digital identity will follow and the perception of the life scene and the app as the service agent will also follow. There are no other end devices that match the smartphone on the most critical dimensions of the individualness, privacy, and the ubiquitous nature as needed by a portal carrier.
第三,端设备的通信功能和服务对接功能将逐步分离。随着可对接的服务越来越多样化,用一个端设备“包打天下”已不可能,但每个端设备均自带通信功能亦不可取。Apple watch 和 iPhone 之间的关系是耐人寻味的:iPhone 作为通信枢纽和客户端信息处理枢纽,Apple watch 作为专项信息采集和有限信息展示的附属设备,二者之间通过近场通信联系起来。当然,二者都是苹果自家人,数据流处在统一掌控之下。一家掌控,分离总是有限的、紧耦合的。但是,做得初一,就做得十五,今后各种分离将层出不穷,混战也将随之高潮迭起。今天是 Alexa 刮旋风,明天兴许就是谁下暴雨。如果手机厂商格局再大一点,在区块链的帮助下,在数据的采集方面对各种附属端设备的贡献进行客观的记录,据此在数据和收益的分享方面做出与各自贡献对等的合理安排,说不定某种松耦合形式的分离就会生米做成熟饭,端的生态到那时定会别样红火。可以设想,在一个陌生的地方,你从怀里掏出一张软软的薄薄的可折叠的电子地图,展开以后像一张真的地图那么大,却又像手机地图一样方便地触摸操作甚至可以结合语音操作,把它关联到你的手机上。当然,这张图也可以没有实物只有投影。而你的手机只管通信,所有的操控和展现都在这张图上完成,根本不需要掏出手机。这样的手机也许从头至尾就根本无需拿在“手”里,甚至可以穿在脚上,逐渐演化成为“脚机”……
Third, there will be separation between the communication function of a terminal device and the demanded service function. As the service grows more and more diversified, it becomes impossible for one end device to handle all types of service needs. But it is not desirable for each end device to come with its own communication function. The relationship between Apple Watch and iPhone is intriguing in this regard: iPhone serves as the communication hub as well as the client information processing hub while Apple Watch functions as a special device for information collection and limited information display. They are connected through a "near field communication" link. Of course, both are Apple's products in one family, the data flow is therefore under a unified control. In such a setting, they are tightly coupled, and the separation is always limited. However, this mode sheds lights to the future when all kinds of separation may be required but they should also be connected in some way. If the mobile phone manufacturers keep an open mind, they can use the block chain technology in data collection with a variety of ancillary equipment to make an objective record of the respective contributions and accordingly make reasonable arrangements with regards to the data and proceeds sharing. A loose coupling of the separation will then evolve and mature, promoting the rapid ecological development of end devices in all kinds of forms. It is imaginable that, when we are in a new place, we can take out from our pocket a soft thin foldable electronic map. This map, when unfolded, looks as big as a real paper map, but it works conveniently just like a mobile map app: it responds to the touch operations and may even accommodate speech instructions to associate with our phone. Of course, this map can also simply be a virtual projection, not necessarily taking the form of a real object. Our phone only needs to take care of communication, all the control and display are accomplished on the map, and we do not even need to physically take out the phone. Such a phone may never need to be held in hands, we may even wear the phone on the foot, and the hand mobile device gradually evolves into a "foot phone" ... ...
Alexa旋风带给你的机会和启发是什么,想好了吗?
Are you ready for the opportunity and inspirations brought by the Alexa whirlwind?
Translated by: Dr. Wei Li based on GNMT
本文获作者白硕老师授权转载和翻译,特此感谢,原文链接:“入口载体”之争
【Related】
S. Bai: Natural Language Caterpillar Breaks through Chomsky's Castle
S. Bai: Fight for New Portals
【李白对话录系列】
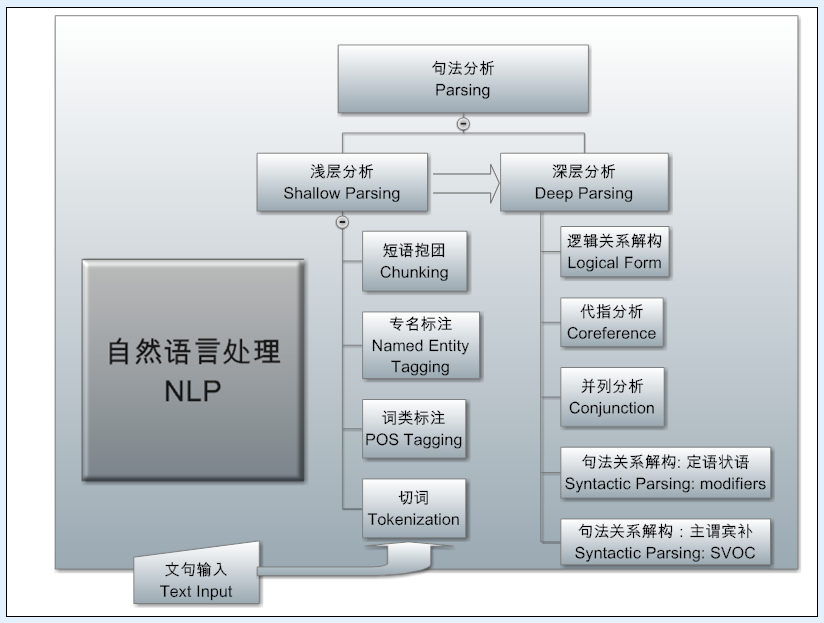
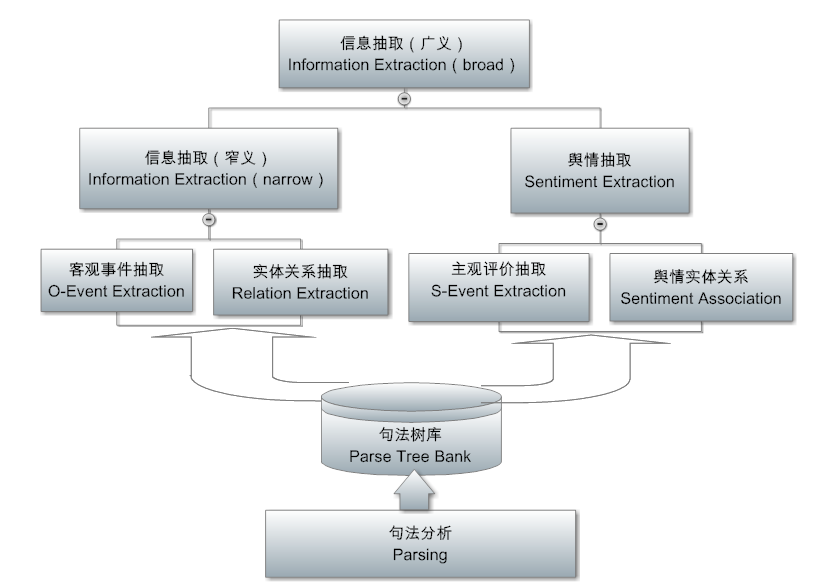
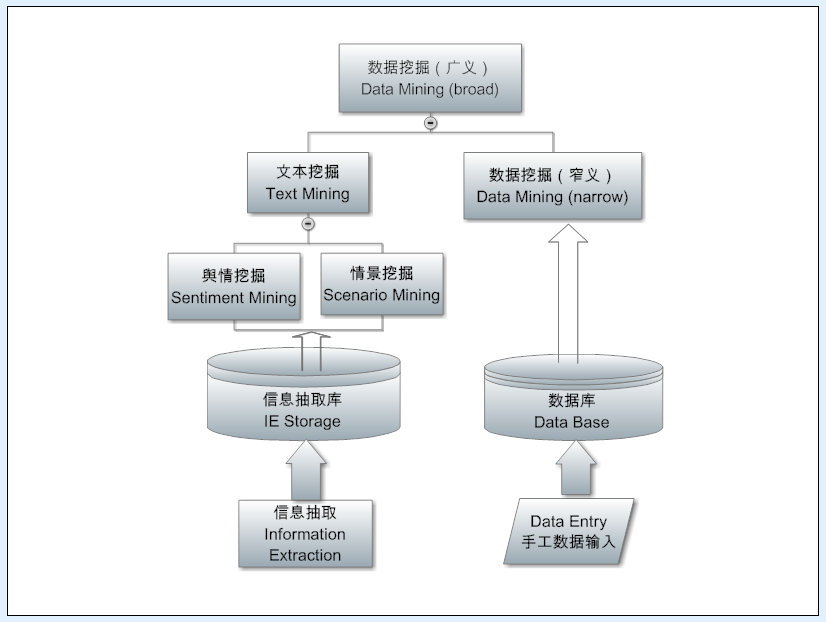
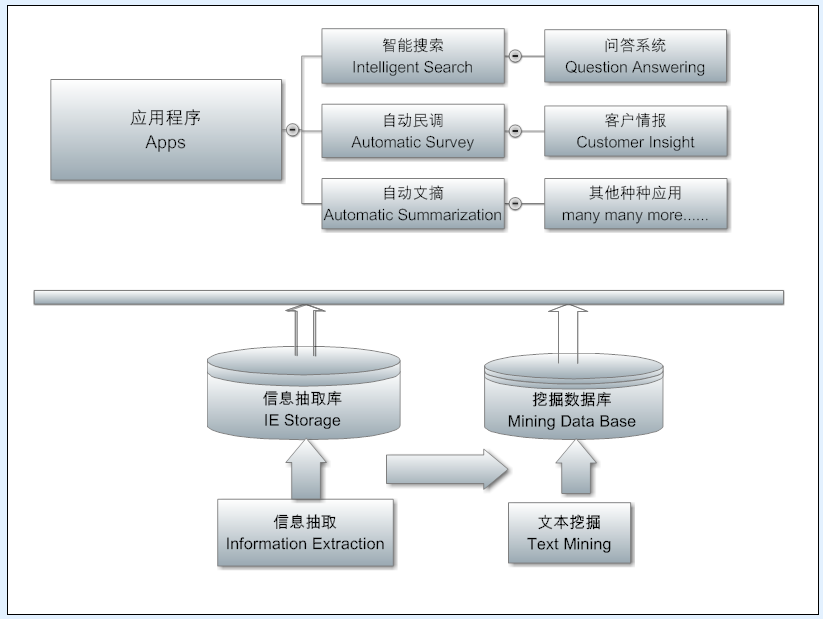
中文处理
Parsing
【置顶:立委NLP博文一览】
《朝华午拾》总目录