【原立委按:微信泥沙龙,谈笑鸿儒,高朋满座,信马由缰,言无所忌,摘之与同仁分享。】
李:
今儿个咱要吐槽乔老爷,不吐不快。
开题:乔姆斯基,对领域的误导,或负面影响,与他对语言学的革命性贡献,一样大。
他的hierarchy,是天才绝顶的理论,是不可泄露的天机,从而奠定了形式语言的基础,用来创造、解释,或编译计算机语言,是完美的指导。可是,完美往上走一步,就成谬误。乔姆斯基拿这套理论,硬往自然语言套,导致整个领域,在所谓自然语言是free,还是sensitive,还是 mildly sensitive等不靠谱的争论中,陷入泥潭。太多的人被引入歧途,理所当然地认定,因为自然语言复杂,因此需要 powerful的文法。这个 “powerful”,是世界上用的最误导的词。
工程师发现,有限状态好用,但经不起理论家的批判:你那玩意儿太低级,不够 powerful,只能拿来凑合事儿。实际上,做过大工程的人都明白,对象的复杂,并不是使用复杂机制的理由,有本事使用简单机制对付复杂的对象,才是高手。
乔姆斯基最大的误导就是,用所谓自然语言的center递归性,一杆子打死有限状态,他所举的center递归的英语实例,牵强和罕见到了几乎可笑的地步,绝非自然语言的本性。结果一代人还是信服他了,彻底地被洗脑,理所当然以为必须超越有限状态才可以做自然语言深度分析。
为了所谓语言的递归性,人脑,或电脑,必须有个堆栈的结构才好,这离语言事实太远,也违背了人脑短期记忆的限制。世界上哪里有人说话,只管开门而不关门,只加左括号不加右括号,一直悬着吊着的?最多三重门吧,一般人就受不了了。就算你是超人,你受得了,你的受众也受不了,无法 parse 啊。说话不是为了交流,难道是故意难为人,为了人不懂你而说话?不 make sense 嘛。
既然如此,为什么要把不超过三层的center循环,硬要归结成似乎是无限层的递归?
毛:
递归成了他的宗教。
李:
不错。乔老爷的递归误导语言学,坑了NLP太久。我对他的语言学不感冒,对他对NLP的误导,更感觉痛心。一个如此聪明强大的人,他一旦误导就可以耽误一代人。被耽误的这一代是我的前辈一代(上个世纪70年代80年代),他们在自然语言理解上的工作几乎一律为玩具系统,在实际应用上无所作为,从而直接导致了下一代人的反叛。老一代被打得稀里哗啦,逐渐退出主流舞台。
在过去30年中,统计NLP的所有成就,都是对乔姆斯基的实际批判,因为几乎所有这些模型,都是建立在ngram的有限状态模式的基础之上。
洪:
从乔姆斯基的所作所为,就能分出构造机器智能和解构人类智能难度上的差异。他五十年代略施小计就把形式语言夯成了计算机的Cornerstone,可是穷毕生精力,总是在重构其语言学理论。
毛:
如果没有乔老的那些理论,人们能做出计算机语言编译吗?)
洪:
语法mapping到语义,总是要做的,不必须用形式语言,就像现在做nlp的人也不必须懂语言学。还是 David Marr,David Rumelhart 等立意高远,总想找到人机等不同智能实现上的共通计算机制。
刘:
Marr 也是人神级别的
毛:
跟上面问题类似的是:如果没有图灵和冯诺依曼的理论,人们会造出计算机么?
洪:
Babbage的分析机可行,Ada的程序/算法也早可行。其实,问题不在于出冯诺依曼还是马诺依曼,问题在于,不管他们的理论表面上如何不同,可能都受同样的约束,能力上可都能都等价。而Chomsky 研究的是这些约束能力。
毛:
那图灵不是更加么?
洪:
Turing 从机器一侧,Chomsky从人一侧。)
李:
洪爷说的是事实,过去三十年不懂语言学做NLP的占压倒多数。但那不是健康状态。不过,语言学里面也很混杂,进来的人很容易迷糊。但是,语言学里面确实有一些指导性的东西,了解与不了解大不一样。比如索绪尔,就值得琢磨。索绪尔说的大多是原则性的,有哲学的意味,是传统的非科学性的语言学,特别具有宏观指导意义,可以提醒自己不至于陷入细节的纠缠,而忘记了方向。他谈的是共性与个性的关系,语言和言语,规则与习惯,共时与现时,都很洞察、到位。
白:
我觉得线速、柔性很关键,多层次递归和远距离相关必须搞定。方法不限,八仙过海。
李:
那些已经搞定了,伪歧义也不是问题,都搞定了。有一种叫做cascaded FSA的方法,与软件工程的做法极其类似,就能搞定这些。前提是指挥者架构者不能失去全局,要胸怀索绪尔,而不是乔姆斯基。架构和interfaces设计好,下面就是模块的开发,匠人的干活,可以做到很深,接近逻辑表达,比典型的chomsky CFG文法深透。传统规则系统受乔姆斯基CFG影响太大,很不好用,而且也无线性算法,所陷入的困境与当年神经网络以及一切单层的统计系统类似。正如多层的深度学习被认为是AI的突破一样,有限状态一多层,一 cascade,以前天大的困难,递归啊远距离啊伪歧义啊,就消解于无形。
白:
数学上的函数复合。
李:
就这么一个简单的道理,结果至今批判规则系统的人,还在打稻草人,以为规则系统都是CFG那么愚蠢和单层。
乔姆斯基对nlp的误导,还在于它的短语结构的表达法。那个phrase structure破树,叠床架屋,为了追求所谓语言共性,太多的assumptions,既不经济也不好用,却长期成为 community standards,误导了不知多少人。起码误导了 PennTree,通过它误导了整个领域。,
白:
某种意义上,nlp是应用驱动的。与应用匹配,Ngram也不算误导。与应用不匹配,HPSG也算误导。抽象的误导不误导,让语言学家掐去吧。一个topic问题,扯了这么多年。)
李:
语言学家打烂仗的事儿多了,说起来这与乔老爷也有很大关系。有个 self,相关的所谓 Binding Theory也是论文无数,大多垃圾,这与老乔的负面影响直接相关。为追求 universal grammar,和脱离语义的generalizations,走火入魔,大多是无谓的口水战争,既不能推进科学,也不能推进应用,唯一的好处是帮助了很多语言学博士的选题,培养出一茬接一茬的语言学博士。可是,毕业了还是找不到工作。老乔由于其超凡的智力和名气,帮助提升了语言学的地位,但他没有能力影响市场,结果是全世界语言学家过剩,懂得茴字五种写法的落魄腐儒,如过江之鲫,谁能给他们就业机会?
这里面的要害在,所有的语言分析,不可能为分析而分析,都是为了求解语义的某种需要,可老乔强调的语法纯粹性,要脱离语义才好研究终极的机制,这个argument有历史的革命意义,有某种学术价值,但非常容易形而上学和片面化,结果是语言学家脱离了目的,脱离了需要,在争论一种分析,或一个模型与另一种的优劣。其实这些相争的方案,只要系统内部相谐,都大同小异,根本就没什么本质区别,而且没有客观的可量度的评判标准,那还不打成一锅粥。
刘:
摆脱语义,直接进入语用?
李:
哪里,乔老爷是要直接进入共产主义,要世界大同。他对语义不感兴趣,更甭提语用。语义在他属于逻辑,不属于严格意义的语言学。句法语义是分割开来的两个范畴,句法必须自制。
白:
句法自制是错误的。
李:
对传统语言学完全不分家的那种分析,老乔有革命意义,也确实推进了结构研究,但凡事都是过犹不及。句法自制推向极端,就是本末倒置,失去方向。
我做博士的时候,在一个小组会上,举一些汉语的例子,作为证据反对一刀切的句法自制,说老乔有偏差,看到的语言事实不够,结果被我导师劈头盖脸批了一通,言下之意,不知天高地厚。我当然口服心不服。问题是,我一辈子只思考一个问题,只要醒着,头脑里除了语言,就是文法,除了词汇,就是结构,突然有一天觉得自己通达了,看穿了语言学上帝,乔姆斯基。原来,智商高,不见得离真理近,智者乔老爷,也不例外。有人说老乔外语不大行,看到的现象大多局限于英语,偏见难免。的确,懂汉语的人很难完全信服什么句法自制:句法形式的约束和语义的约束很难截然分开,否则连“我鸡吃了”和“鸡我吃了”都搞不定。
说起外语,到了我们的年代,俄语退居其后了,所以我本科的二外选的是法语,到研究生才选了俄语做三外,不过全还给老师了。虽然语言是还给老师,体悟到的语言学却长存,所以也不冤。到 30 年后的今天主持 multilingual program,带着参考书,我还一样可以指导法语和俄语的 NLP 研发,语言的不同,换汤不换药也。
洪:
老乔不是上帝,他只是让咱看到来自造物主的理性之光。
李:
形式语言理论,非人力可为,绝对属于天机,单凭这,乔就是人神。吐槽乔老爷,一次抱怨完,明儿依旧是偶像。
不管我怎么批判乔姆斯基,我还是服他到不行:他老人家的威望可以把 Universal Grammar 这种乍听很荒唐的观念,转化成一个让人仰视的语言哲学理念。UG 的真理之光由此不被遮蔽。当然最厉害的还是他的 hierarchy 形式语言理论,那几乎不可能是人的理论,那是上帝之光,尽管乔老爷在描述的时候,不免机械主义,hence 造成了极大的误导。
话说回来,没有自然语言的数学化研究和启示,他老人家也提不出形式语言理论来。至少从形式上,他能把人类语言和电脑语言统一起来,达到一种人力难以企及的高度。如果没有乔姆斯基,电脑理呆们打死也不会对词法分析,句法分析,语义求解,parsing 等感兴趣,并如数家珍地谈论这些语言学的概念。这是其一。
其二,正因为乔老爷自己也知道他的形式语言理论的抽象过头了,难以回到自然语言的地面,才有他穷其一生在自然语言的语言学方面的继续革命,革自己的命,花样翻新,试图找到一个终极的普遍文法的自然语言解构。这次他就没有那么幸运了,虽然在学界依然所向披靡,无人能敌,但却与电脑科学渐行渐远,被连接语言学和电脑应用的计算语言学领域所抛弃。也许不该说抛弃,但是自然语言领域大多把他当菩萨供起来,敬神鬼而远之,没多少人愿意跟他走。
首发科学网 【泥沙龙笔记:乔姆斯基批判】
【相关】
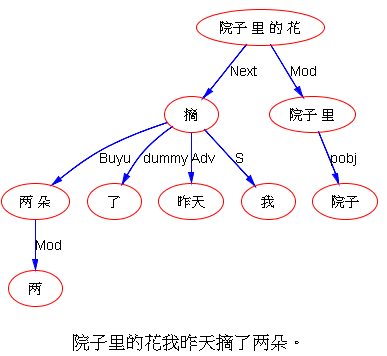
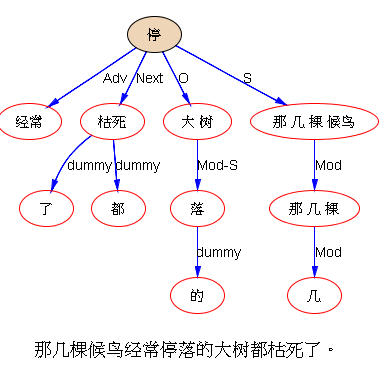
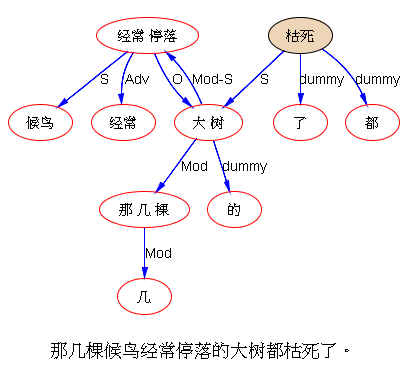
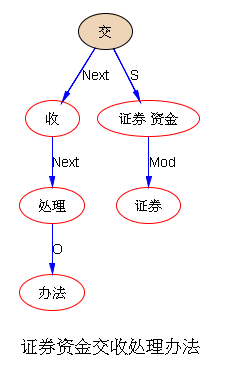






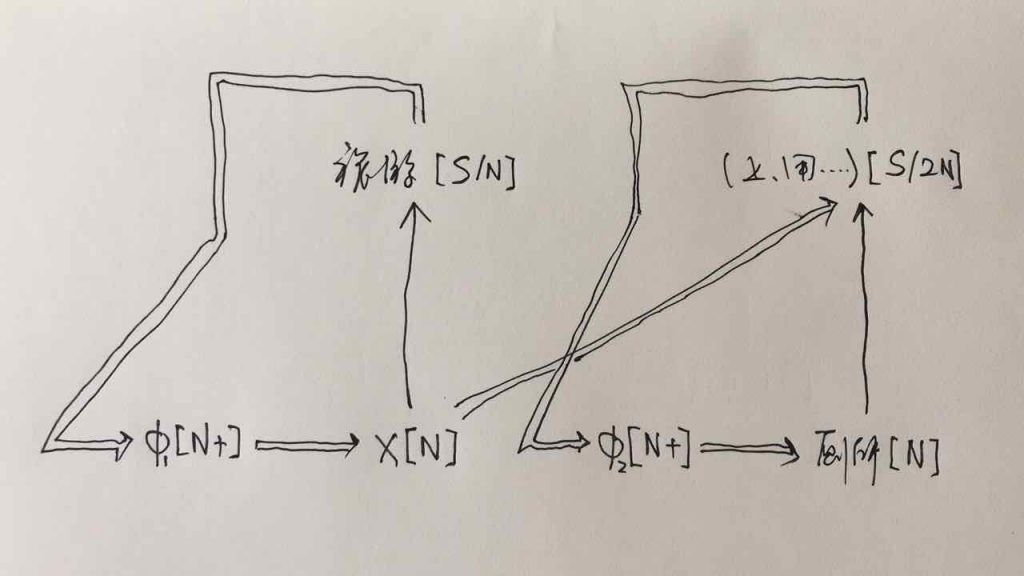
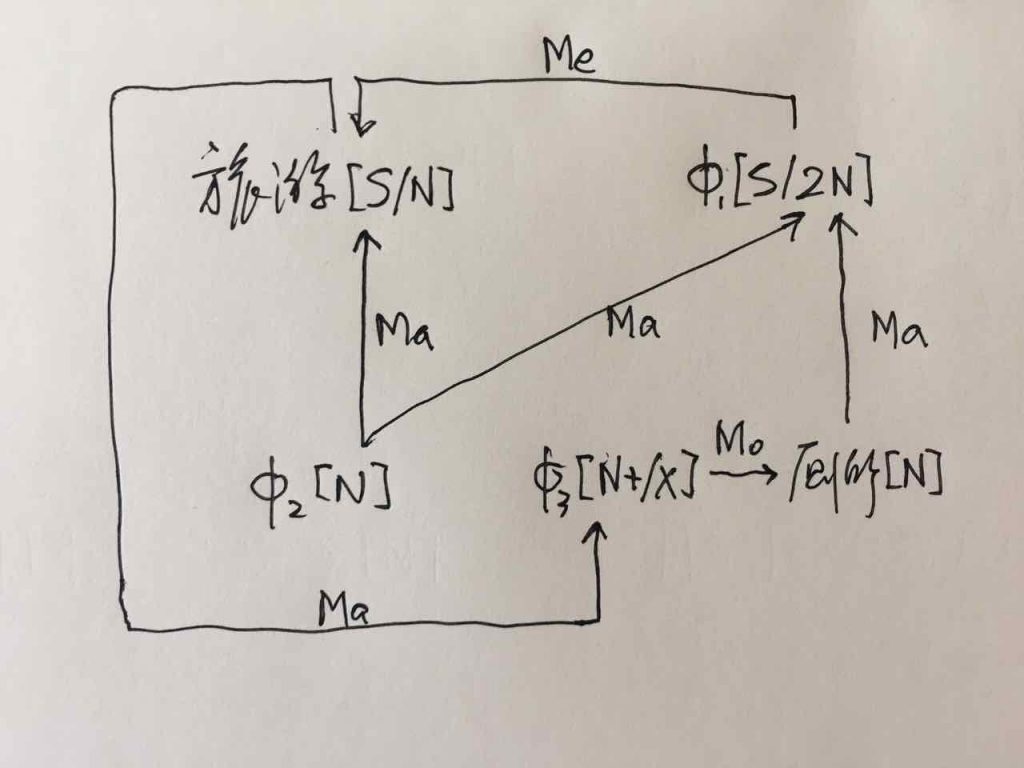
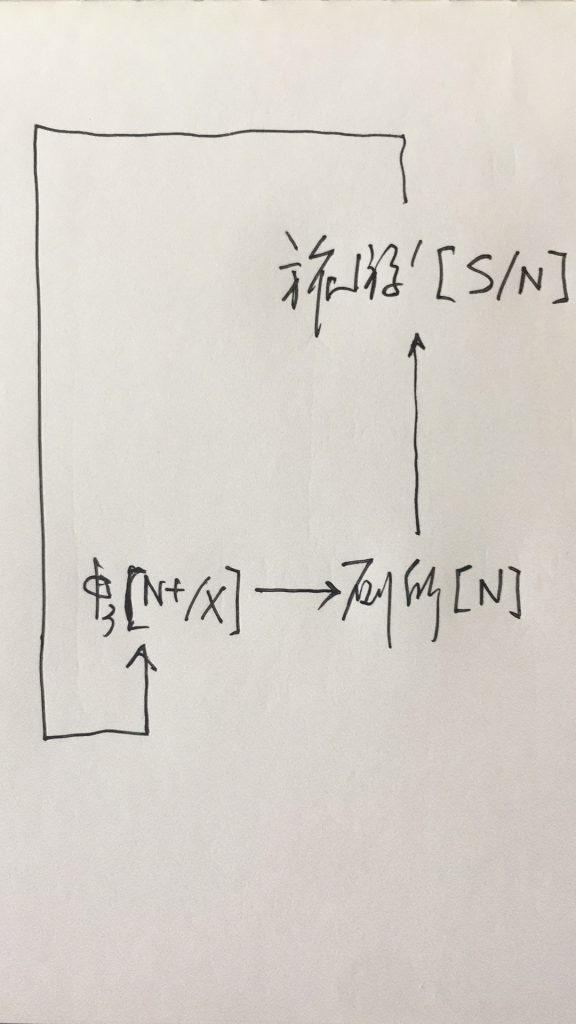
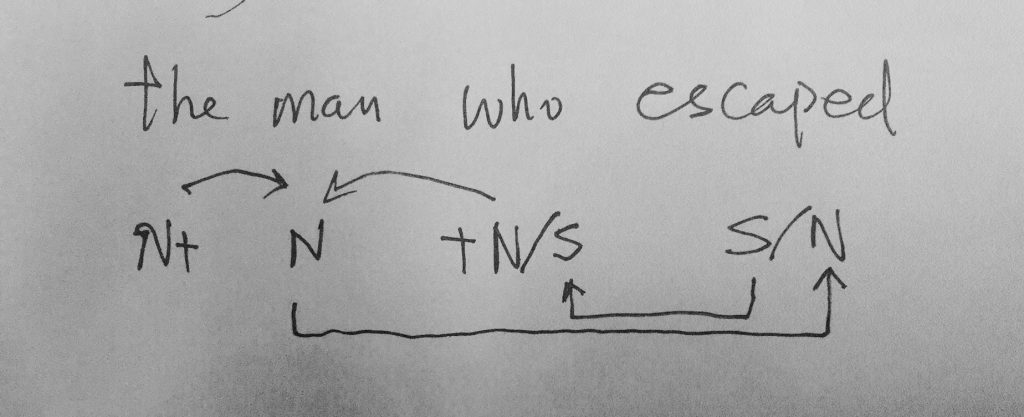
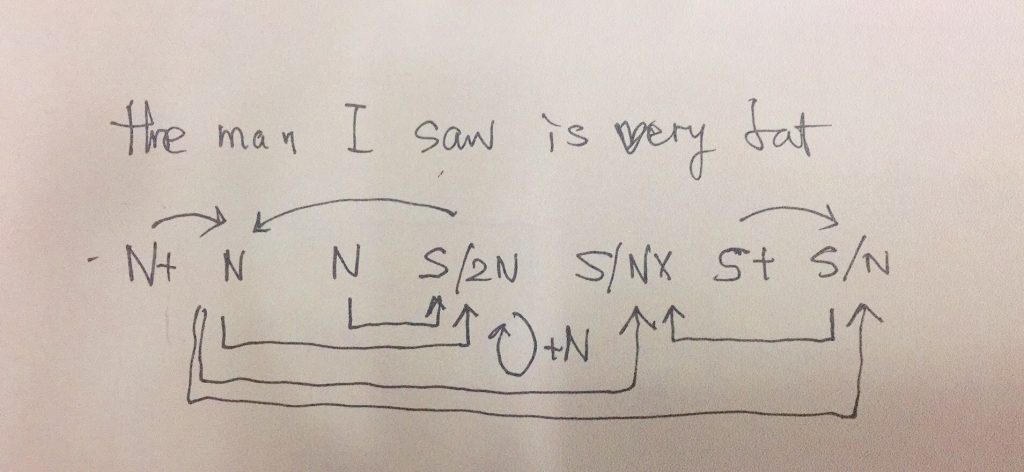

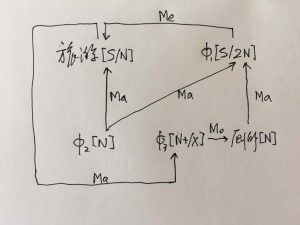

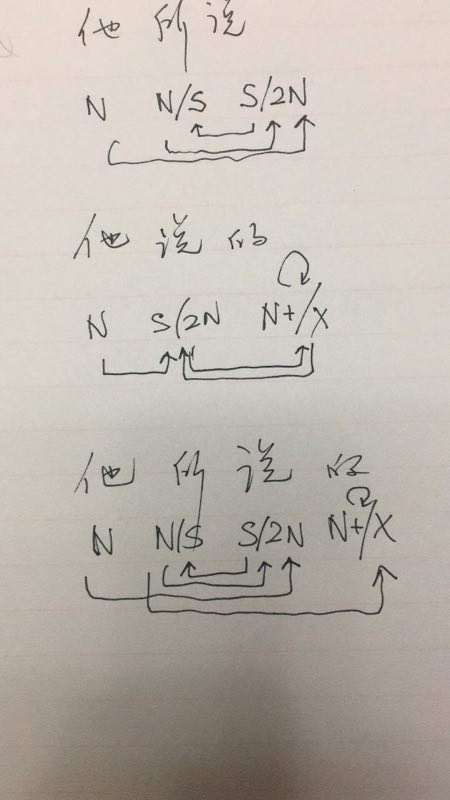

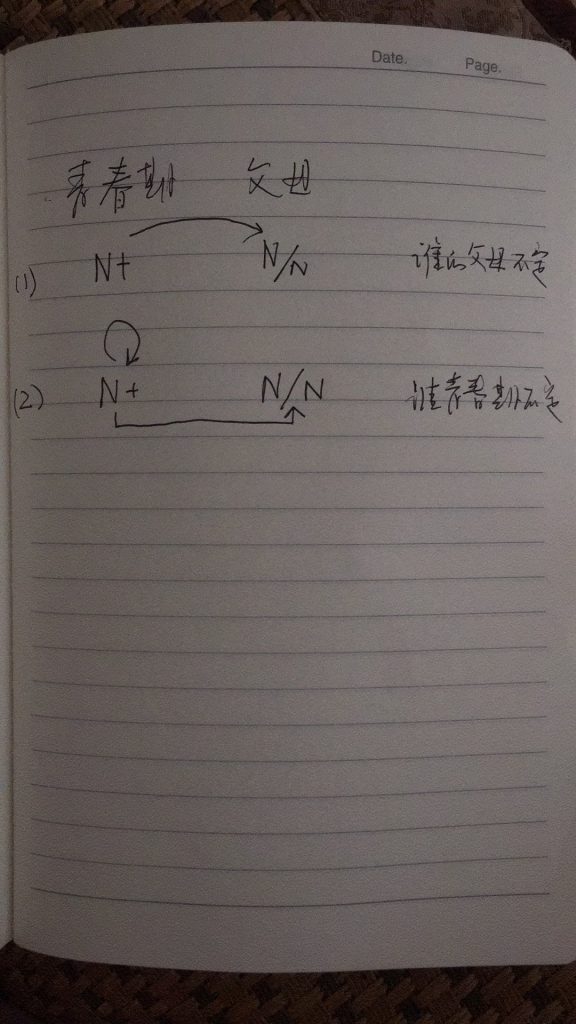



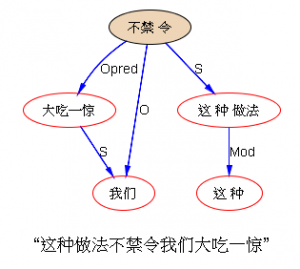
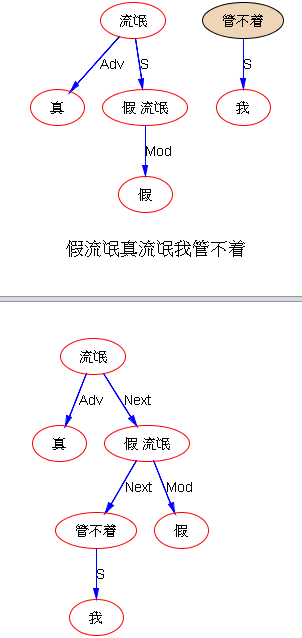
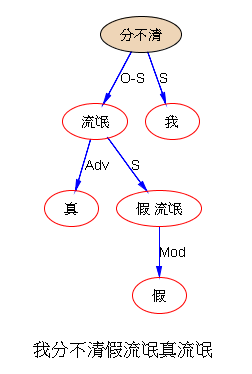
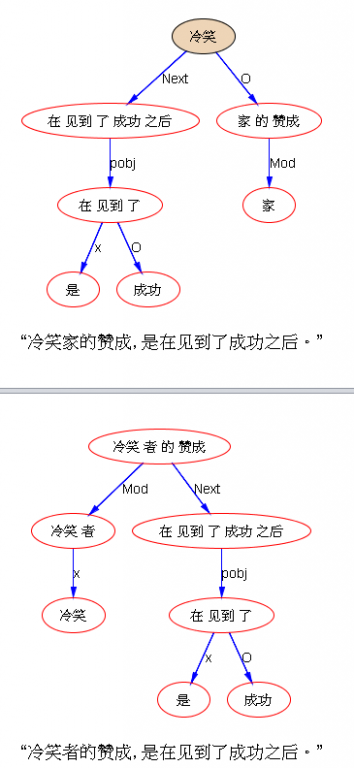

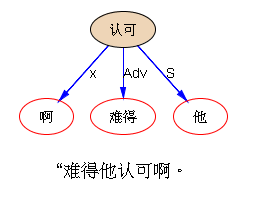
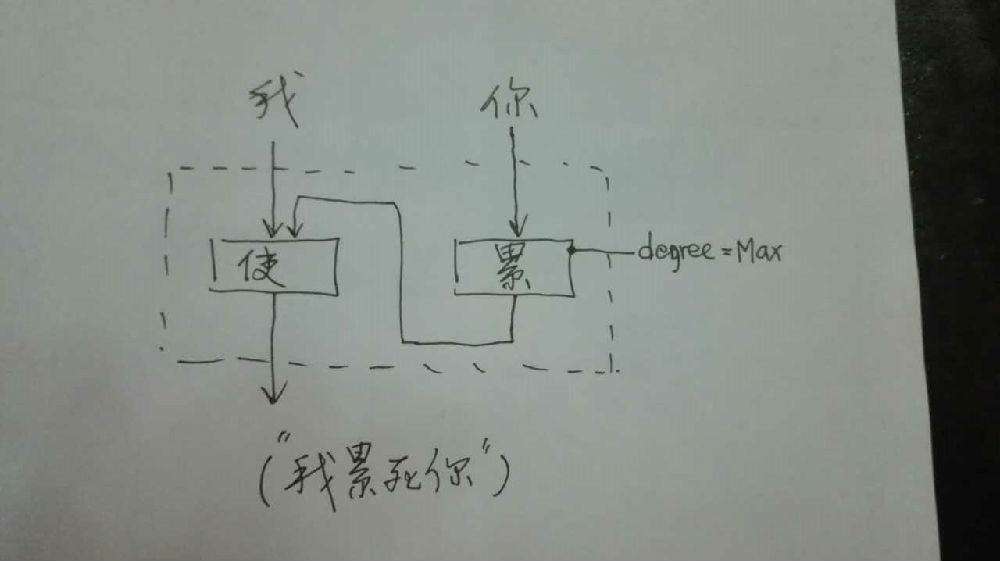
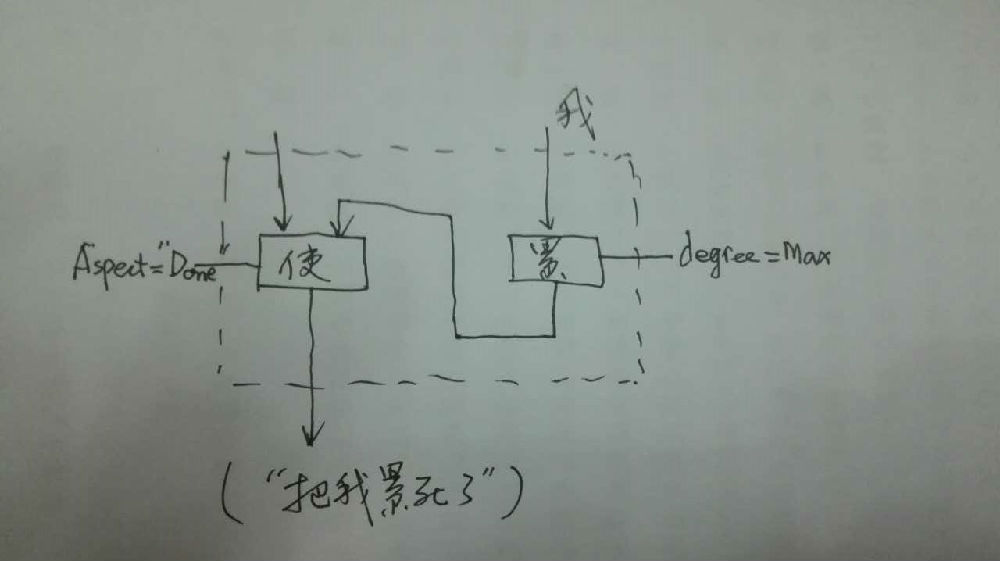
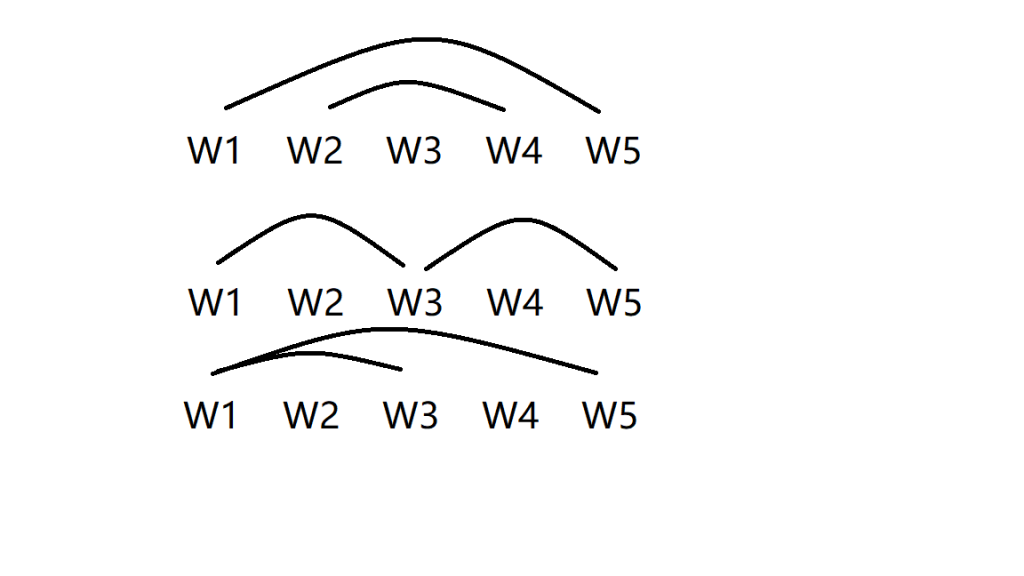
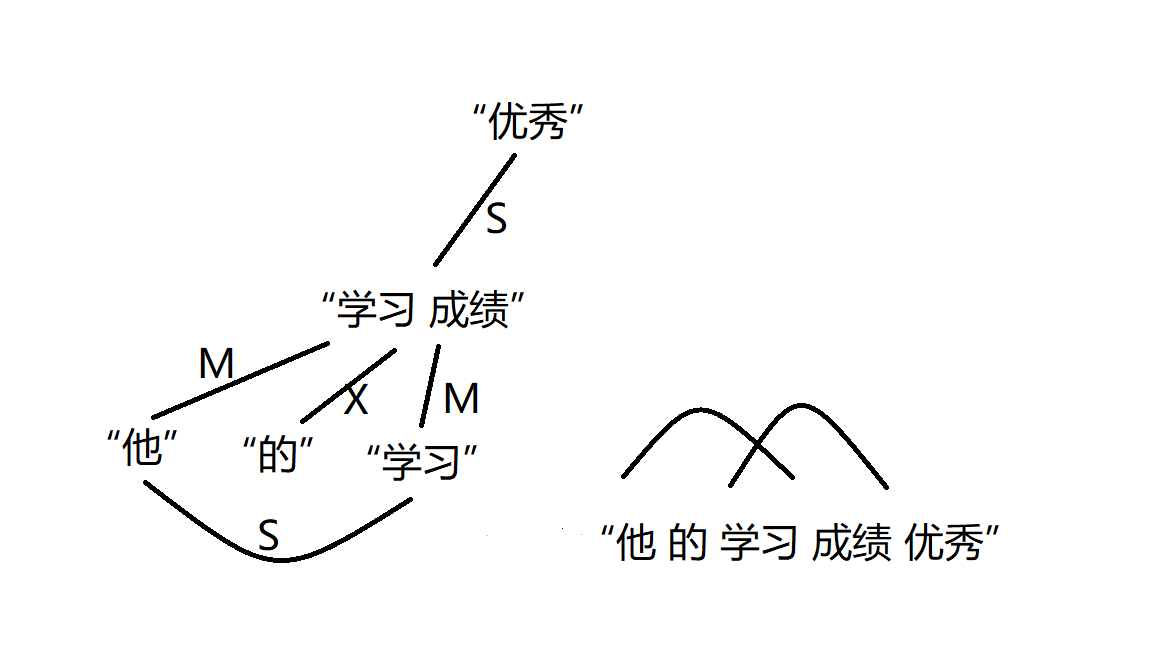 如果DG(Dependency Grammar)揉进了浅层的短语结构及其边界,先做了合成词“学习 成绩”,那么把“他”与合成词内部的“学习”连接成主谓关系,是交叉。但是如果不引入短语结构,一切节点都是终极节点,实行彻底的原汁原味的依存关系(DG)表达,那么“他”作为主语连接给“学习”以及“学习”作为修饰语连接给“成绩”,并没有真正交叉,只是层次(configuration)显得乱了。但是DG的最大特点(或缺点)就是打破层次,只论二元。多年来我们在DG中部分引入 PHG (Phrase Structure Grammar) 短语结构表达,也是为了弥补这个缺陷。
如果DG(Dependency Grammar)揉进了浅层的短语结构及其边界,先做了合成词“学习 成绩”,那么把“他”与合成词内部的“学习”连接成主谓关系,是交叉。但是如果不引入短语结构,一切节点都是终极节点,实行彻底的原汁原味的依存关系(DG)表达,那么“他”作为主语连接给“学习”以及“学习”作为修饰语连接给“成绩”,并没有真正交叉,只是层次(configuration)显得乱了。但是DG的最大特点(或缺点)就是打破层次,只论二元。多年来我们在DG中部分引入 PHG (Phrase Structure Grammar) 短语结构表达,也是为了弥补这个缺陷。